
I lost my pg_control again (... yet another data recovery story)
Co-Authored-By: mei
 this blogpost is a spiritual continuation of the data recovery post from February.
this blogpost is a spiritual continuation of the data recovery post from February.i really hope this doesn't become a bi-monthly series
So, we had another outage on the 11th of March; Timeline and details are in the linked postmortem, but to cut the story short, when bringing the DB back up, I was greeted with the following errors from PostgreSQL:
[4395] LOG: invalid primary checkpoint record
[4395] PANIC: could not locate a valid checkpoint record
(datestamps removed for brevity)
While it looked like data corruption (maybe an SSD failure, or something with the SATA controller), the reality turned out to be somewhat less exciting:
- /var/lib/postgresql/ is on another partition, which I have to manually decrypt and mount each restart
- the postgresql service was erroneously set to automatically start on boot, despite its directory not being mounted
- Alpine's init scripts helpfully ran initdb on the empty directory (on the unencrypted rootfs)
- I mounted the partition without stopping the already-running postgresql daemon (I didn't know about it)
- I ran service postgresql restart instead of just start out of habit
- The old, empty instance of postgres scribbled over the decrypted database while shutting down
So, by default, PostgreSQL will just crash if it gets an empty data directory, but a distribution init script gave us a fun evening instead... Learning from past mistakes, we did have proper backups (a cron job running pg_dump every night); but how fun is it to just restore the DB, and losing a few morning hours of data as a result?
Instead, I checked for damage with find . -mmin 60. Thankfully, no applications were able to connect to the database, so the corruption was quite limited - in fact, the only modified files were:
- postmaster.opts (the last command line used to start the server)
- global/pg_control (our hero, more about them later)
- pg_wal/archive_status (empty directory; used for WAL-based backups and replication)
The archive_status directory was always empty according to my backups. This means that only one important file got overwritten...
What the heck is pg_control!?
According to pgPedia, pg_control is an 8KB bin file, storing metadata about the internal PostgreSQL state. In reality, the data structure itself is much smaller than said 8KB:
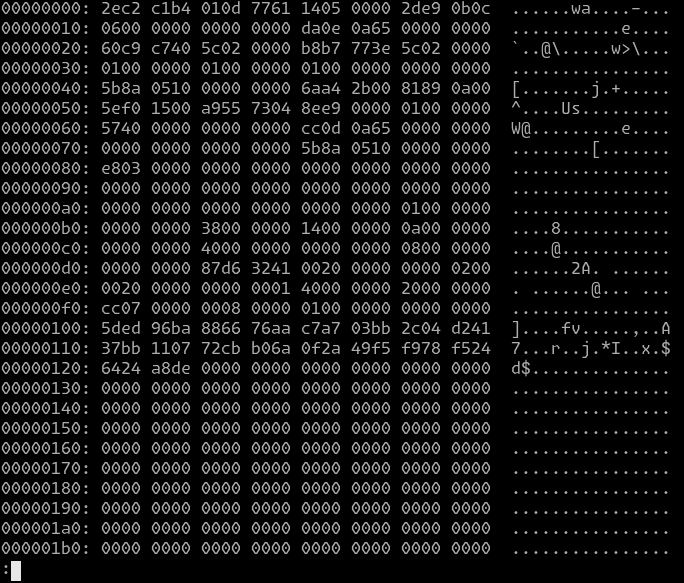 Picture 2 - a hexdump of the pg_control file. According to comments in the source code, it's supposed to fit within one block on all common disks
Picture 2 - a hexdump of the pg_control file. According to comments in the source code, it's supposed to fit within one block on all common disks
The pgPedia page also links to the header file, which defines the structure itself. Furthermore, we also learn about two utilities that dump the metadata for debugging purposes: pg_controldata and pg_resetwal.
$ pg_controldata .
pg_control version number: 1300
Catalog version number: 202107181
Database system identifier: 7023096444886303278
Database cluster state: in production
pg_control last modified: Tue Sep 19 23:12:58 2023
Latest checkpoint location: 25C/40C7C960
Latest checkpoint's REDO location: 25C/3E77B7B8
Latest checkpoint's REDO WAL file: 000000010000025C0000003E
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:268798555
Latest checkpoint's NextOID: 2860138
Latest checkpoint's NextMultiXactId: 690561
Latest checkpoint's NextMultiOffset: 1437790
Latest checkpoint's oldestXID: 74667433
Latest checkpoint's oldestXID's DB: 59790
Latest checkpoint's oldestActiveXID: 268798555
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 16471
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Tue Sep 19 23:08:28 2023
(...)
what pg_controldata tells us about the file; illustrative, uses old data
The takeaway from this is that no actual data has been lost or damaged. Looking at what pg_controldata dumped out, it seemed that it might be possible to recreate the metadata with just the data that we still had on the drive.
By sheer coincidence, I still had PostgreSQL filesystem dumps from the previous blogpost, which have proven extremely useful during the recovery. I mounted one of them, extracted the pg_control file, and tried manually changing the checkpoint values, having the header file with the struct open on a second display. However, this has proven to be somewhat of a fool's errand as there was a CRC32C checksum at the end of the structure, which I wasn't able to successfully compute at that point.
One friend (hi q3k!) suggested that I could patch out the CRC32 check in the postgres executable, but I saw that as a somewhat drastic approach. Moreover, at that point, I didn't even know what the proper values for the checkpoint fields should be. Somewhen around that time mei came over, and we decided it would be very romantic if we stared at PostgreSQL source for the next n hours together.
How does this all connect together?
The database data consists of three important parts:
- the data files, also known as the heap, which store the actual data structures of the database — much like a C program's heap stores the data structures the program operates on (except, you know, on disk, so the concept of a pointer probably looks a bit different)
- the Write-Ahead Log (WAL), which is the magic sauce that keeps the database in a consistent state in case of a system crash
- the pg_control file, which specifies which parts of the WAL are still relevant
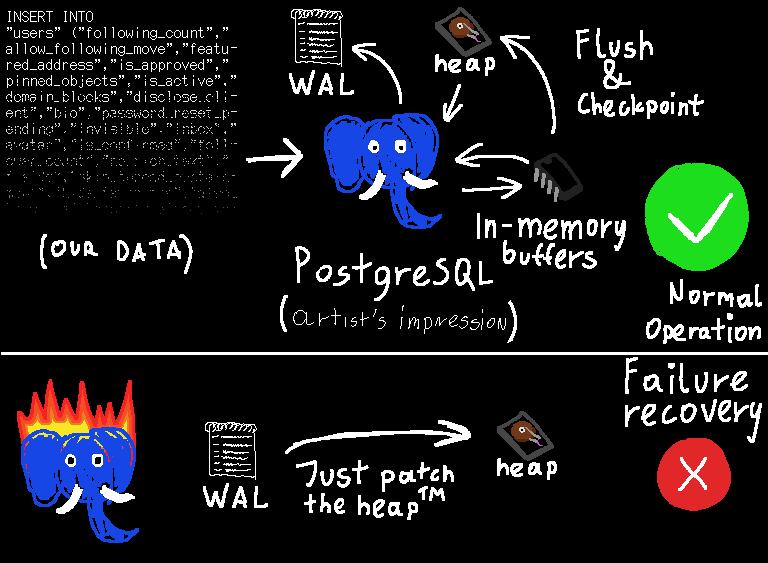 Picture 3 - somewhat simplified description of how PostgreSQL works with WALs enabled
Picture 3 - somewhat simplified description of how PostgreSQL works with WALs enabled
The basic idea of Write-Ahead Logging is that, before anything is done to the actual data files, a description of the entire transaction is flushed out into the WAL, such that we're sure it will persist in the event of a crash.
This description needs to be carefully designed to not rely on any of the heap data that is about to be modified — if the power cuts out in the middle of a disk block being written, it might become invalid and unreadable. We also don't know if the modifications described in the WAL have already been applied to the heap. But as long as the description is sufficiently self-contained, we can just replay it from the beginning to fix any inconsistencies caused by the power interruption.
A very simple WAL could contain a list of "writing the following data at the following offsets in the heap", all aligned to a multiple of a disk block. This would work, but slowly — doing things this way introduces write amplification, where each small change requires, say, 4KB to describe in the WAL.
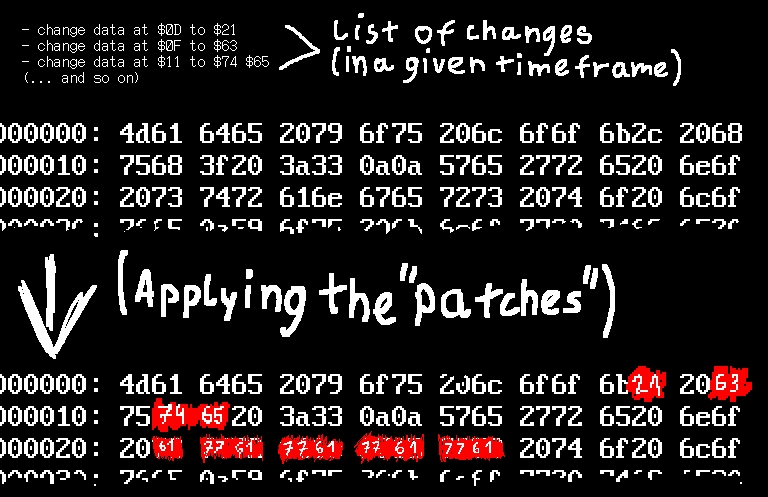 Picture 4 - an oversimplified description of how a WAL works for recovery at a lower level
Picture 4 - an oversimplified description of how a WAL works for recovery at a lower level
To remedy this, PostgreSQL splits up the WAL by emitting a checkpoint regularly — any crash recovery will be started from one. When a block is first touched after a checkpoint, its contents get copied into the WAL, in a manner entirely analogous to that described above. This only occurs the first time a block is modified — on subsequent changes, it's safe to save only the few bytes that are actually changing — or use any other high-level description like "insert an element into this B-tree".
Apart from the atomicity and durability, WALs are used in the implementation of physical replication, incremental backups, and point-in-time recovery. The documentation even lists the following property:
> WAL also makes it possible to support on-line backup and point-in-time recovery, as described in Section 26.3. By archiving the WAL data we can support reverting to any time instant covered by the available WAL data: we simply install a prior physical backup of the database, and replay the WAL just as far as the desired time. What's more, the physical backup doesn't have to be an instantaneous snapshot of the database state — if it is made over some period of time, then replaying the WAL for that period will fix any internal inconsistencies.~ PostgreSQL documentation, Section 30.3. Write-Ahead Logging (WAL)
Without any familiarity with the internals, this might sound like black magic. But once you understand that the WAL is basically a fancy list of instructions of the form "overwrite this part of the heap with the following data", it becomes reasonably intuitive.
This also describes what a possible fix could be, if we had been doing backups a bit differently — start with a filesystem backup, and apply the WALs, including the fresh ones that haven't had a chance to end up in a backup yet. The backups we had, though, were ASCII SQL, dumped with pg_dump. They have the advantage of being simple to understand and hard to fuck up, but do limit our options as far as cool tricks go ;3
While familiarising ourselves with all of the related concepts, we got to the documentation page on WAL Internals; it ends with this wonderful, coincidentally relevant quote:
> To deal with the case where pg_control is corrupt, we should support the possibility of scanning existing WAL segments in reverse order — newest to oldest — in order to find the latest checkpoint. This has not been implemented yet. pg_control is small enough (less than one disk page) that it is not subject to partial-write problems, and as of this writing there have been no reports of database failures due solely to the inability to read pg_control itself. So while it is theoretically a weak spot, pg_control does not seem to be a problem in practice.Getting to this part literally had me going "ohh, this is me! it's me! i'm the first!". It also gave us a pretty good idea of what we need to do — find a checkpoint in the WAL, and put it into pg_control. Though, unlike what the documentation describes, we opted for the first checkpoint we could find in the WAL segments on disk — starting WAL replay too late would result in corruption, but starting too early will only just take some more time to finish.
aight, let's fix it
We ran pg_waldump on the first WAL segment in the database files, and found the first CHECKPOINT line:
$ pg_waldump 000000010000040400000004
(...)
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 404/04973878, prev 404/04973840, desc: CHECKPOINT_ONLINE redo 404/41E1150; tli 1; prev tli 1; fpw true; xid 0:405051005; oid 4796146; multi 1120555; offset 2309972; oldest xid 209563934 in DB 16892; oldest multi 1 in DB 16471; oldest/newest commit timestamp xid: 0/0; oldest running xid 405051005; online
(...)
(note: this field scrolls)
The LSN of this log entry is 404/04973878. This means that it has been emitted after 0x40404973878 bytes of WAL, measured across the entire lifetime of the database. The low 24 bits are an offset into the WAL file, and the rest corresponds to the filename — though this split is configurable.
At this point, we stared at the hexdump of the WAL file, and determined that the structure of a CHECKPOINT_ONLINE entry is exactly what we need for the checkPointCopy field of pg_control — after you strip off a header common to all types of WAL entries.
As far as other values in pg_control go, we had a known-good version of pg_control from September 2023 backed up, which we used to make some... educated guesses about some fields. This has proven essential as not all of the fields can be guessed by parsing the WAL — mostly pertaining to the configuration of the database.
Behold, the script we used to do the dirty deed:
from crc32c import crc32c # pip install crc32c
# pwntools is a powerful drug... you can
# only ever pretend to stay away from it
def p32(x):
return x.to_bytes(4, 'little')
def p64(x):
return x.to_bytes(8, 'little')
checkpoint_lsn = 0x40404973878
wal_file = '000000010000040400000004'
old_pg_control = 'pg_control.old'
with open(wal_file, 'rb') as wal:
wal.seek(checkpoint_lsn % (1 << 24) + 0x1a)
checkpoint = wal.read(0x58)
print(checkpoint)
# only used for data that is probably the same
# as when the DB was first created
with open(old_pg_control, 'rb') as old:
old = old.read()
# structure info taken from pg_control.h
# http://git.postgresql.org/gitweb?p=postgresql.git;a=blob;f=src/include/catalog/pg_control.h
pg_control = b''
pg_control += p64(7023096444886303278) # system_identifier
pg_control += p32(1300) # pg_control_version
pg_control += p32(202107181) # catalog_version_no
pg_control += p64(6) # state (DB_IN_PRODUCTION)
pg_control += p64(1710206333) # time
pg_control += p64(checkpoint_lsn)
pg_control += checkpoint
pg_control += old[0x80:0x120] # starting at unloggedLSN, everything up to the CRC
pg_control += p32(crc32c(pg_control))
with open('pg_control.restored', 'wb') as f:
pg_control += bytes(8192 - len(pg_control))
f.write(pg_control)
print("New pg_control written. May Cthulhu be kind today.")
This dumps a file called pg_control.restored. When used as a replacement for our overwritten pg_control...
[22857] LOG: starting PostgreSQL 14.11 on x86_64-alpine-linux-musl, compiled by gcc (Alpine 13.2.1_git20231014) 13.2.1 20231014, 64-bit
(...)
[22865] LOG: database system was interrupted; last known up at 2024-03-12 02:18:53 CET
[22865] LOG: database system was not properly shut down; automatic recovery in progress
[22865] LOG: redo starts at 404/41E1150
[22865] LOG: invalid record length at 404/4BE7FC8: wanted 24, got 0
[22865] LOG: redo done at 404/4BE7FA0 system usage: CPU: user: 0.04 s, system: 0.04 s, elapsed: 0.72 s
[22857] LOG: database system is ready to accept connections
(datestamps removed for brevity)
We get a successful restore!
Worth noting: invalid record length at 404/4BE7FC8: wanted 24, got 0 is apparently an entirely normal way a PG WAL restore can end, and it doesn't signify an error by itself - it's just a weird way of spelling "EOF, i'm done here". Great UX, folks.
Lessons learnt
Restoring from a backup would've arguably made more sense, because only a relatively small amount of data was at stake. At some point during the night, we even started a restore in the background, but it was taking literal hours — I blame the sheer amount of data we have, and an old SSD for the poor random I/O speeds. The latter should be remedied when I deploy a new server in the coming weeks.
Nonetheless, it was a great learning experience (and was just plain fun! <3)
We also learned a lot about the possibility of having a lower-level backup of a PostgreSQL database. The simplicity of pg_dump is still very appealing, but an incremental WAL-based backup might soon become a part of the setup — running in tandem with a full pg_dump every night.
In the future, I foresee a smaller amount of "fun" issues like the two recently outlined on my weblog, because I won't have to run my infra on a shoestring budget. Having the necessary IOPS to do more frequent backups instead of leaving them to be done once at night will be a gamechanger — I'm really excited for everything the new hardware (sakamoto Mk5, coming in a few weeks) will allow us to do :3
Huge thanks to Miya, lauren, irth, Lili, and Linus for proofreading this post!
Also, many thanks to mei for helping out with the recovery, co-writing this blogpost, and hanging out in general! <3
