
Stakes bigger than life: fixing ext4 under pressure
Last September, we've had an unplanned reboot on sakamoto (one of my servers - likely the one serving you this page). This in itself isn't that big of a deal, but the chaos that ensued afterwards got weird really quickly.
As a preface, the relevant parts of sakamoto currently work more or less like this:
- Alpine Linux on host
- / on a SATA SSD, ext4 (defaults)
- array of spinning rust, with ZFS (including native encryption)
- "band-aid" SSD LUKS solution: huge file under / that's LUKS encrypted and has an ext4 partition underneath
The last part isn't even close to best practices, but I deemed it "good enough" as a temporary solution. And, as we all know, temporary solutions last the longest... :p
Leading to the incident: early 2023
In late March of last year, I decided to move our (then fully unencrypted) postgres db to a LUKS-backed store; Due to our partition layout (and to minimize downtime), I went with a LUKS-in-a-file based approach, as outlined above.
> I will be pulling postgres down for some LONG overdue maintenance in ~10 minutes. I expect that it will be down for around 10-20 minutes.~ me, March 29th 2023, 17:27 CET
Initially, I created a 64GB file, which seemed plenty big at the time. Everything went well, and I didn't care for a month or two. Then, we wanted to migrate the Matrix db from sqlite to PostgreSQL; That database ended up being almost twice the size of the original partition - so I grew the file with dd oflag=append conv=notrunc, then the LUKS part with cryptsetup resize, and finally, the ext4 FS itself with resize2fs. It worked like a charm; In the coming months, I likely did that once more.
The incident: September 19-20th, 2023
Around 23:22 CEST, the system rebooted. Immediately afterwards, I started bringing up some of the services (a few things have to wait for the filesystems to get decrypted and properly mounted). Then, I hit a brick wall:
mount: /postgres_luks.img: cannot mount; probably corrupted filesystem on /dev/loop0.
dmesg(1) may have more information after failed mount system call.
dmesg, helpfully reported:
EXT4-fs (loop0): VFS: Found ext4 filesystem with invalid superblock checksum. Run e2fsck?
... at which point, I decided not to run fsck, and to make a backup before I do anything else. When recovering data, it's easier to fix *one* problem than *many* stacked problems. If for some reason you're in a similar place right now, please work on a copy.
After having a safe copy, I tried `e2fsck`:
e2fsck 1.47.0 (5-Feb-2023)
ext2fs_open2: Superblock checksum does not match superblock
e2fsck: Superblock invalid, trying backup blocks...
e2fsck: Superblock checksum does not match superblock while trying to open postgres_fckd.img
The superblock could not be read or does not describe a valid ext2/ext3/ext4
filesystem. If the device is valid and it really contains an ext2/ext3/ext4
filesystem (and not swap or ufs or something else), then the superblock
is corrupt, and you might try running e2fsck with an alternate superblock:
e2fsck -b 8193
or
e2fsck -b 32768
As trying different superblocks didn't help, I began ducking1,
#1
we duck in this mothafucka,
get your sensitive ass back to google
which yielded a lore.kernel.org message.
It seems that with some kernels from 2022-2023, it's possible to hit
a bug where if you resize a part more than once and never unmount it,
the journal is fscked2. Or at least that's my hypothesis.
#2
fscked is, of course, the past tense of "file system consistency check", or fsck for short. don't let anyone tell you that's a backronym /s
My own, personal ext4 hell
I didn't have any recent PostgreSQL backups. Hell, I wouldn't be writing
this post if I did. There are a bunch of threads on the net about
similar corruptions, but they all either revolve around failing drives
(where trying a different superblock will actually help), or they
end up unanswered. Alas, I did a bunch of reading on the underlying bug,
and made a wild guess: the superblock is likely okay, it's probably
just the checksum that hasn't been flushed to disk.
Let's disable the checksumming!
As per a random stackoverflow answer, you can do that using tune2fs. Except...
# tune2fs -O metadata_csum postgres_fckd.img
tune2fs 1.47.0 (5-Feb-2023)
tune2fs: Superblock checksum does not match superblock while trying to open postgres_fckd.img
Couldn't find valid filesystem superblock.
classic chicken-and-egg problem: you need a working superblock to fix your superblock
Cosplaying as a filesystem maintenance tool
Since virtually all programs from e2fsprogs refuse to function on a broken superblock (dumpe2fs, which displays metadata being the only exception), I was left with no option but to understand the structure myself.
Reading through the ext4 wiki has proven to be a great resource in understanding how everything fits together. Finding the start of the superblock in the dump can be done either through reading dumpe2fs's output, or by manually inspecting the hexdump - a good thing to look out for is the last mountpoint (superblock offset +0x88). If your partition was created with a recent mkfs.ext4 and default options, the first superblock likely starts at offset 0x400 (1024).
According to the wiki page on partition layout, superblock's byte 0x175
is s_checksum_type -
"Metadata checksum algorithm type. The only valid value is 1 (crc32c)";
Naively trying to change that field to 0 yields the following error:
EXT4-fs (loop0): VFS: Found ext4 filesystem with unknown checksum algorithm.
(truly) uncharted territory from here onwards!
So it really has to be 0x01. But then, how does tune2fs disable the checksums? Searching for "csum" in the same table, we find s_feature_ro_compat at 0x64. It's a bitfield, and value 0x400 corresponds to flag "This filesystem supports metadata checksumming (...)"
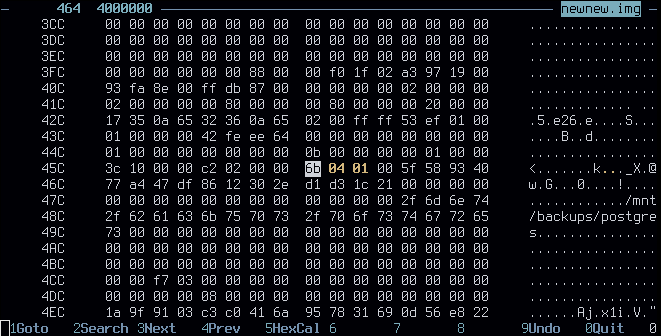
offending field; file offset 0x464 (0x400+0x64). note the little endian
In my case, that bitfield was set to 6b 04 01 00; I hastily patched that to 6b 00 00 00 (... which also accidentally disabled something else - docs don't even document what 0x10000 does o.o). Afterwards, I tried mounting it with mount -o ro,noload postgres_fckd.img postgres, and it succeeded! The data was intact! After nearly 2 hours, I announced good news and breathed a sigh of relief.
It's worth noting that before I found the correct field to edit, I got stuck on a few different things. Most notably, a bitfield s_feature_incompat with offset 0x60 has a similar flag "Metadata checksum seed is stored in the superblock. (...)"; I also tried zeroing the CRC32 found later in the superblock, but that didn't really do anything. All in all, ~1.5h under pressure isn't a bad time to reverse a part of your FS :)
Conclusions
My main takeaway from this incident was to finally configure daily, automated
PostgreSQL backups. I was procrastinating on doing that, because I wanted to
figure out a resource-effective way to do it incrementally;
Back in the sakamoto Mk4.0 days (Xeon X3360, 8GB RAM),
pg_dump (db) | xz used to consume quite a lot
of IOPS; Nowadays, sakamoto has a CPU several times as fast, and much more
memory, so we can easily get away with a scheduled
pg_dump (db) | zstd -T8 sometime late at night.
And even with our current DB size (~130GB on disk), it compresses to a nice
~20GB (Zstandard is marvellous), which totals just under 150GB for a weekly
retention period.
And well, to show that I learned my lesson: I wrote the backup scripts just after bringing everything back up. At 2am. They've been running flawlessly ever since.
A more general takeaway is that filesystem tools should really allow the user to break their stuff when the user knows what they're doing. I would get away with much, much less stress if tune2fs had a --force option. Moreover, this isn't exclusive to e2fsprogs: extundelete, testdisk and a few other tools also refused to function on that partition, even though the data was fully intact. I see this as a big shortcoming, especially around tools designed around data recovery.
- (ducking): we duck in this mothafucka, get your sensitive ass back to google
- (fscked): fscked is, of course, the past tense of "file system consistency check", or fsck for short. don't let anyone tell you that's a backronym /s
Thanks to irth,
Linus,
Lili,
BluRaf,
ari, and
aviumcaravan
for proofreading this post!
y'all rock <3

Comments:
Wow, this reminds me old times when I was trying to understand in what order to assemble mdadm devices after a crash. 200% of adrenaline in the blood for 2h, but the respect of other admins when I succeeded was priceless 😎
Mmike at 02.03.2024, 14:51:18Good! You are doing backups now. Do test the restore too!
Alex at 02.03.2024, 19:48:20Reminds me of the time I accidentally wiped my VM host server while attempting to do some maintenance. I ended up writing a 1GB image to the beginning of the boot drive, utterly hosing the LVM metadata on it along with a chunk of the data. I was mainly concerned with the VM images stored on it, which were installed a good bit after the initial setup of the server. I figured that the disk images were in a later part of the disk, so they were likely salvageable. I had (foolishly) never backed up the LVM metadata file from the server, but luckily, I was able to copy the LVM metadata off of one of the other LVM volumes, and with that, I was able to successfully bring back up the volume and mount it. fsck noted a bunch of corruption, but as I suspected, the virtual machine images were not affected by the corruption. I now have the LVM metadata backed up properly (along with backups for the contents of the VMs as well) :)
4censord at 12.03.2024, 19:28:56Regarding backups, i can wholeheartedly recommend pgbackrest (https://pgbackrest.org/) as a continuos backup tool. It has save my databases more that once after hardware (and human) errors.
By commenting, you agree for the session cookie to be stored on your device ;p